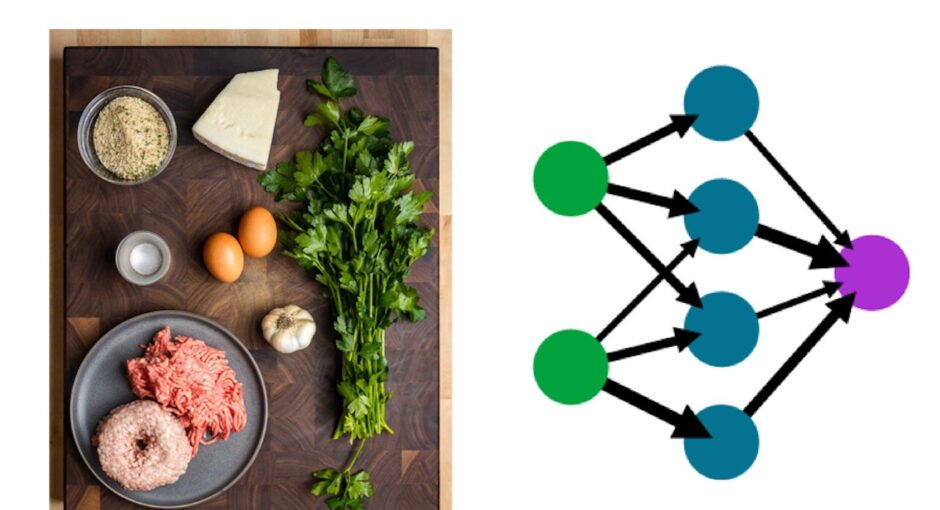
Cooking is an art that often requires a meticulous balance of various ingredients to achieve the perfect flavor. This process is not unlike the method used to train neural networks in the field of machine learning.
Consider the creation of a meatball recipe, where each ingredient—meat, white bread, bread crumbs, parsley, basil, egg yolks, milk, and garlic—represents a different parameter in the neural network. These ingredients, much like the weights and biases in the network, are measured and added in specific amounts to form a cohesive mixture.

Once the ingredients are combined to form the meatball mixture, denoted as ‘z’, this blend is akin to the output generated from a neural network’s linear transformation, expressed in PyTorch as torch.matmul(x, w) + b. Just as the quality of the meatballs depends on the harmony of its ingredients, the performance of a neural network relies on the proper calibration of its parameters.
A true test of both comes when it’s time for evaluation. If the meatballs are too moist, or perhaps lacking in saltiness, or missing a kick of spice – it indicates that adjustments are needed. This is comparable to a neural network’s loss function, which evaluates the difference between the predicted output ‘z’ and the actual target ‘y’. The loss function, such as binary cross-entropy, measures the accuracy of the neural network’s predictions.
When the meatballs don’t taste quite right, a cook might make several adjustments: adding more breadcrumbs for texture, a pinch of salt, and perhaps an extra dash of garlic. In the realm of neural networks, this adjustment process is called backpropagation. It involves calculating the necessary changes to the weights and biases to improve the output. Backpropagation guides these adjustments by indicating both the direction and magnitude of changes needed to enhance the model’s predictions.
The loss function is critical—it tells us what needs to be fine-tuned in our recipe. Just as it provides the cook with feedback on multiple flavor dimensions, it also provides the gradient (the direction and amount of adjustment needed for each parameter) to reduce the loss in a neural network.
Perfecting the meatball recipe is an iterative process, requiring multiple adjustments and taste tests. Similarly, training a neural network involves multiple epochs or cycles of adjusting the weights and biases based on the loss function, with the goal of improving the model’s performance with each iteration. This type of feedback-driven learning, known as supervised learning, relies on examples with known “correct” answers to guide the optimization process.
Beyond Recipes: Unsupervised Discovery
Imagine you’re a chef tasked with creating appetizers for a party with diverse tastes, but you have no specific recipes or guest preferences. This scenario is akin to unsupervised learning. Your goal is to analyze your ingredients, group them based on flavors and textures, and design appealing platters that showcase different combinations. You discover patterns without predefined labels, much like unsupervised algorithms do with data.
In Conclusion
The art of cooking serves as an excellent analogy for understanding the training of neural networks. Both involve meticulous adjustments and continuous evaluation to achieve the desired outcome. Through backpropagation and loss function optimization, neural networks refine their parameters, just as a chef tweaks their recipe. And just as chefs sometimes venture beyond familiar recipes, unsupervised learning allows for the discovery of new patterns and insights within data.



Social Profiles